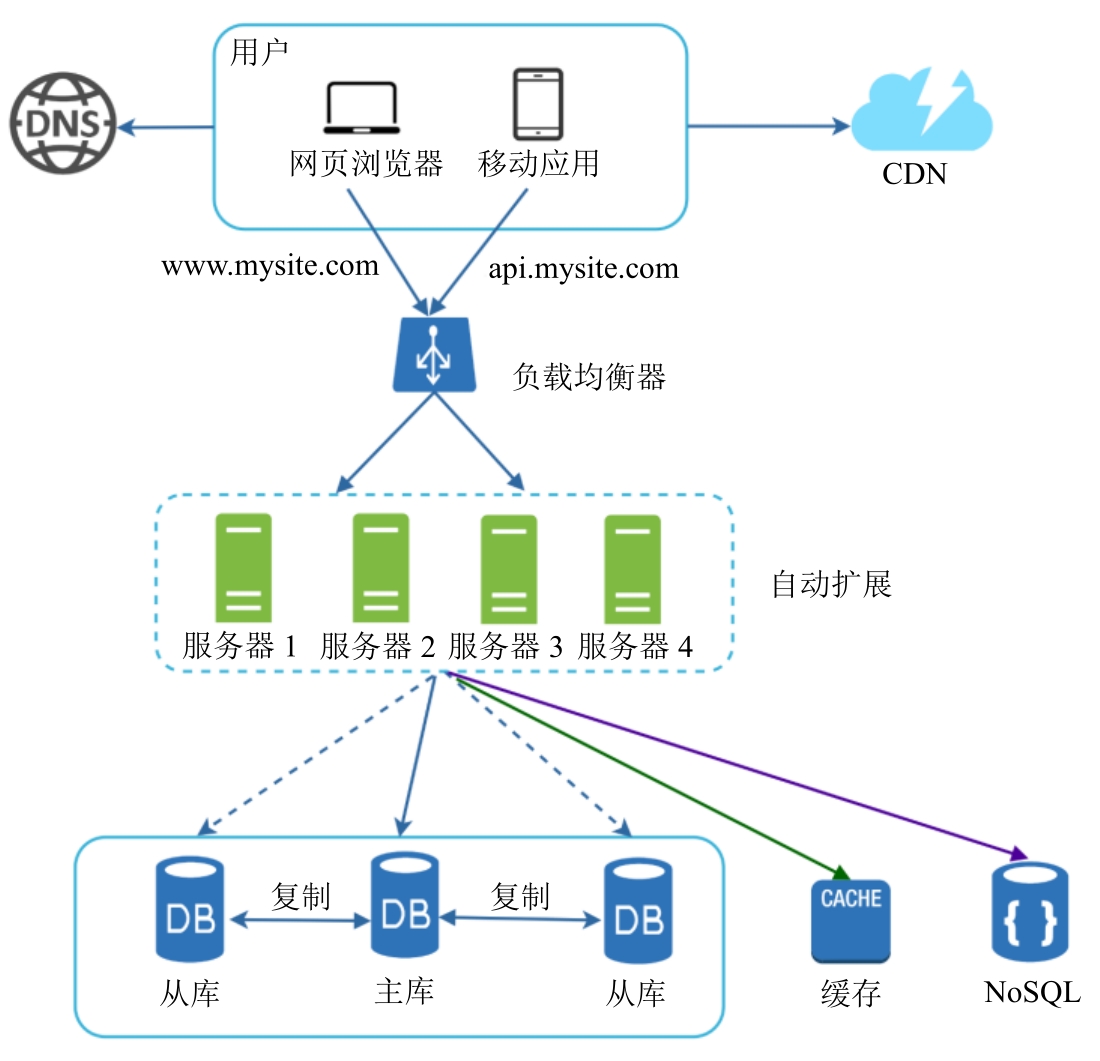
1. 从0到100万用户的扩展
1.1 考虑因素
- 因此对于大型应用来说,采用横向扩展更合适一些
- 采用负载均衡器(nginx, k8s, istio等)
- 数据库主从复制,数据库扩展
- 使用缓存,CDN
- 让网络层无状态,方便扩展
- 多数据中心
- 使用消息队列
- 记录日志、收集指标与自动化
2. 系统设计方案
2.1 限流器
考虑点1:接口访问时间频率,用户id,用户IP,用户设备等特征。
考虑点2:是否分布式限流,通知用户,容错性。
设计
既可以在客户端也可以在服务器端实现限流器,客户端容易伪造。
创建一个中间件作为限流器,用它来限制对API的请求,限流器通常在一个叫作API网关的组件中实现。
常见限流算法
参考:https://www.liuvv.com/p/8bf1212a.html
- 漏桶算法(固定速率消费),适合要求出栈速度稳定的场景。
- 令牌桶算法(动态速率生产),允许在很短时间内出现突发流量。只要还有代币,请求就可以通过。
2.2 聊天系统
目标:
- 一对一聊天,消息的传输延时低。
- 小型群组聊天(最多100人)。
- 展示在线状态。
- 支持多设备,即同一个账号可以同时在多个设备上登录。
- 推送通知。
- 聊天应用可支持5000万DAU。
设计:
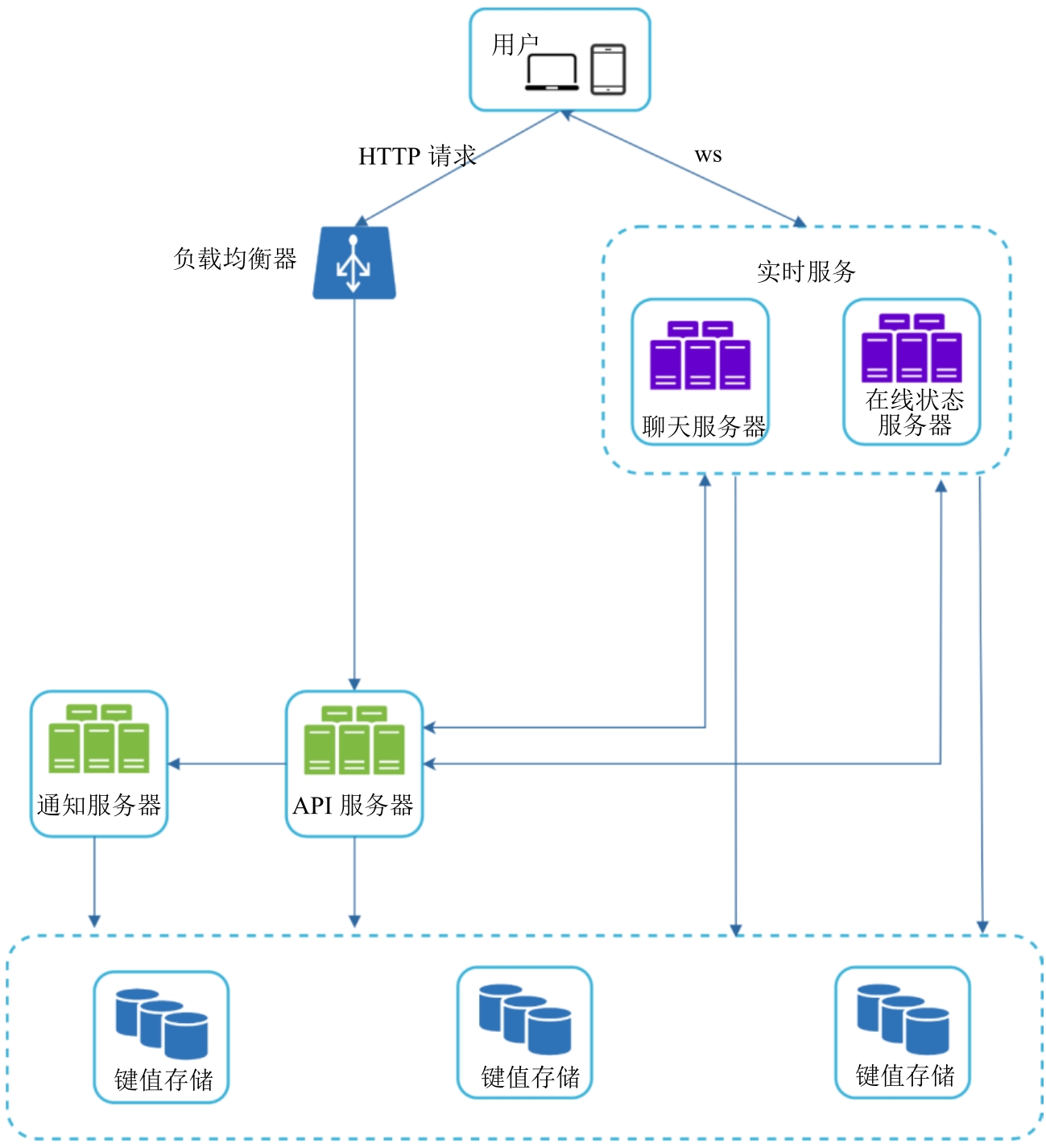
- WebSocket用于客户端和服务器之间的实时通信。
- 传递实时消息的聊天服务器、管理在线状态的在线状态服务器、发送推送通知的推送通知服务器、持久化聊天历史的键值存储和提供其他功能的API服务器。
- 在聊天系统中,唯一的有状态服务是聊天服务。这个服务是有状态的,因为每个客户端都维持了一个和聊天服务器的持久连接。
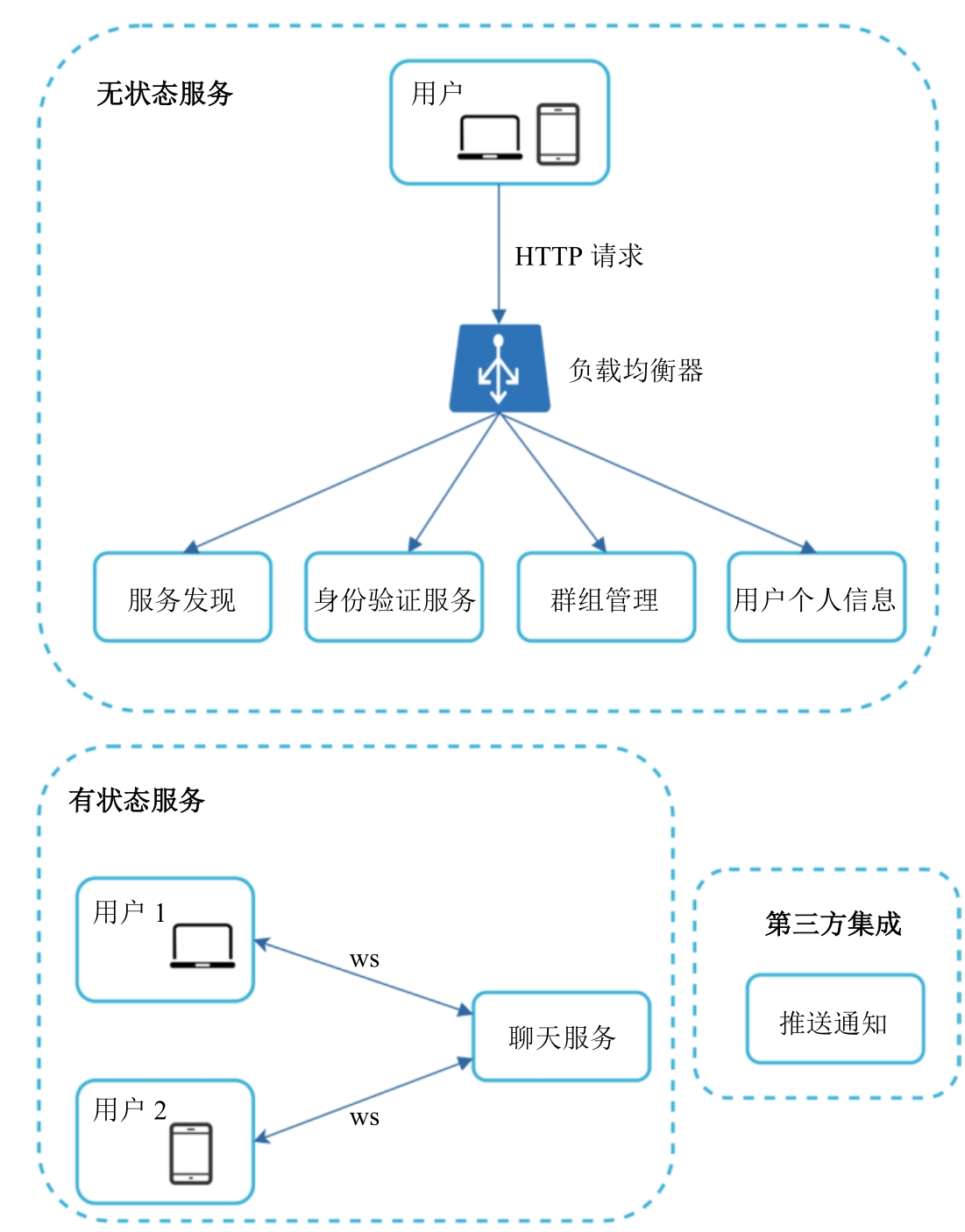
考虑模块
有状态服务:唯一的有状态服务是聊天服务。
第三方集成:推送服务等
存储:
通用数据,比如用户个人信息、设置、用户的好友列表等,这些数据被存储在健壮且可靠的关系型数据库中。
聊天历史数据推荐使用键值存储,关系型数据库不能很好地处理长尾数据。
消息流:
一对一聊天消息流:
1.用户A发送一条聊天消息给聊天服务器1。
2.聊天服务器1从ID生成器处获取一个消息ID。
3.聊天服务器1将消息发送到消息同步队列。
4.将消息存储在键值存储中。
5.a.如果用户B在线,消息将被转发到用户B连接的聊天服务器2上。
5.b.如果用户B不在线,一个推送通知将被发给推送通知服务器。
6.聊天服务器2转发消息给用户B。用户B和聊天服务器2之间存在持久的WebSocket连接。
群聊消息流:
假设群里有3个成员(用户A、B、C)。首先,来自用户A的消息被复制到每个群成员的消息同步队列中:用户B有一个队列,用户C也有一个队列。
你可以把消息同步队列想象成收件箱,每个收件人都有一个。对于群聊,这个设计是合适的。如果群成员非常多,那么为每个成员存储消息副本是不可接受的。
在接收者端,一个接收者可以收到来自多个用户的消息。每个接收者有一个收件箱(消息同步队列),它包含来自不同发送者的消息。
在多个设备之间同步消息
每个设备都维护了一个叫作cur_max_message_id的变量,用于追踪设备上最新消息的ID。
满足以下两个条件的消息被认为是新消息:接收者ID等于现在登录的用户的ID。键值存储中的消息ID大于cur_max_message_id
由于每个设备的cur_max_message_id是不同的,每个设备都可以从键值存储中获取各自的新消息,因此消息同步变得很容易。
显示在线状态:存储和心跳机制。
在线状态广播:只有当用户进群或者手动刷新好友列表时才获取在线状态。
2.3 feed 系统
发布feed
- 将帖子持久化到数据库和缓存中。
- 广播服务(Fanout Service):把新内容推送到好友的news feed中。news feed数据存储在缓存中以便快速获取。
- 通知服务:告知好友有新内容,并发送推送通知。
广播服务
读广播的缺点是因为没有预先计算,所以获取news feed会很慢。
写广播的缺点是如果用户有很多好友,获取好友列表并为所有人生成news feed会很慢且耗时,对不活跃的用户或者那些很少登录的用户,预计算news feed会浪费计算资源。
我们采用了混合方案,因为快速获取news feed很重要,所以我们对大部分用户使用推送模型。对于名人或者有很多好友和粉丝的用户,我们让粉丝按需拉取新内容(news)来避免系统过载。
获取流程
- 如果我们把整个用户和帖子对象都存储在缓存里,占用的内存会非常大,因此只将ID(post_id和user_id)存储在缓存中。
- news feed服务从news feed缓存中获取帖子ID列表。
- news feed服务从用户缓存和帖子缓存中获取完整的用户和帖子对象,来构建完整的news feed。
2.4 搜索补全系统
字典树数据结构
基本的字典树数据结构在节点中存储字符。为了支持按照频率排序,需要在节点中包含频率信息。
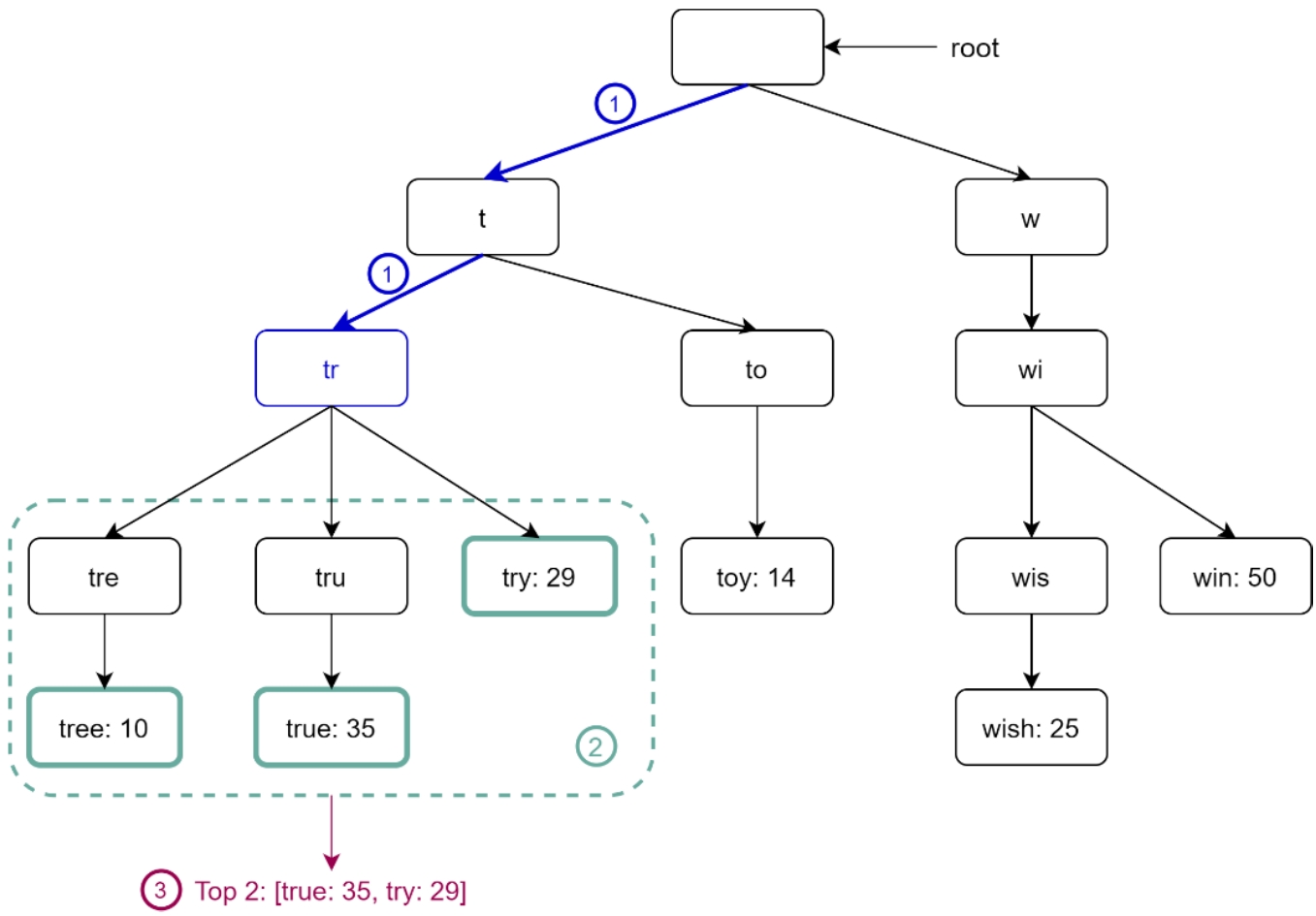
用户在搜索框中输入了“tr”。
第1步:找到前缀节点“tr”。
第2步:遍历子树来获取所有的合格子节点。在这个例子中,节点[tree:10]、[true:35]、[try:29]是合格的。
第3步:对合格的子节点进行排序并获取排在最前面的两个。[true:35]和[try:29]就是有前缀“tr”的排在最前面的两个查询词。
虽然这个算法简单且直接,但是它还是太慢,因为在最坏的情况下,我们需要遍历整个字典树才能获取排名前k的结果。接下来,我们介绍两个优化方法。
- 限制前缀的最大长度(用户很少在搜索框中输入一个长查询词,时间复杂度可以从O(p)降为O(小常数))。
- 在每个节点缓存被高频搜索的查询词(只有排在前5位的查询词被缓存)。

数据收集服务
更新字典树
构建字典树的数据通常都来自数据分析服务(Analytics)或者日志记录服务。
一旦字典树被创建,对高频查询词的建议可能不会经常变化。我们假设字典树每周都重新构建一次。
存储数据分片
可以把第一个字符是“a”到“m”的查询词存储在第一个服务器上,把第一个字符是“n”到“z”的查询词存储在第二个服务器上。
分片映射管理器维护了一个查找数据库,用来确定数据应该被存储在哪个分片上。
3. 系统设计头脑风暴
3.1 网关层
- 域名地址解析到负载均衡器(nginx, k8s service, istio virtual service)
- api网关层,无状态
- bff 服务(鉴权, redis,缓存,限流)
- 安全性,熔断,降级
3.2 微服务层
- 微服务 -> 微服务 [数据库]
- 服务横向扩展,自动伸缩
- RPC协议
3.3 数据层
- 数据库层主从复制,冷热隔离,数据分片
- 加快访问速度:redis, cdn
- 消息队列
3.4 监控层
- 日志,监控
- 收集指标
3.5 部署层
- 自动化部署
4. 参考资料
- 《System Design Interview》

